So recently I was asked about Király's method for generating all graphs from a degree sequence. While refactoring some of the code that I wrote to do this, I also made some tests. Specifically, coverage tests to check that the generation was actually exhaustive. I know it's redundant, but I have good tools to remove duplicate graphs - or I thought that I did…
Here a rough flowchart of the procedure here, starting with a number ('n') that is passed to Dreadnaut (the interface to nAUTy) to generate graphs:

These graphs are grouped by degree sequence, and these degree sequences are fed into the KirályHHGenerator to reconstruct the set of graphs. I think that compare arrow is wrong, but never mind. The point is that the sets should be the same size.
They are for n=5,6,7 but not for 8. Oddly enough, however, there are more in the Király set than in the nAUTy set. The obvious conclusion would be that my duplicate detection is failing - in other words, I am failing to spot an isomorphism between two graphs. For example this pair:

However, two of my methods give different answers for this pair. The signatures method says they are different, while the partition refinement method says they are the same. Odd - and more investigation is needed before I am certain that geng has missed some graphs here...
Here a rough flowchart of the procedure here, starting with a number ('n') that is passed to Dreadnaut (the interface to nAUTy) to generate graphs:
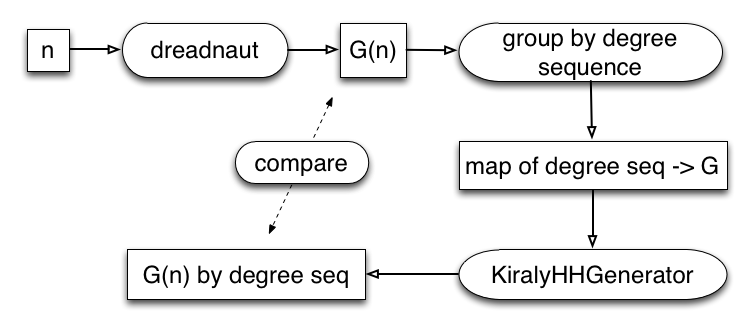
These graphs are grouped by degree sequence, and these degree sequences are fed into the KirályHHGenerator to reconstruct the set of graphs. I think that compare arrow is wrong, but never mind. The point is that the sets should be the same size.
They are for n=5,6,7 but not for 8. Oddly enough, however, there are more in the Király set than in the nAUTy set. The obvious conclusion would be that my duplicate detection is failing - in other words, I am failing to spot an isomorphism between two graphs. For example this pair:

However, two of my methods give different answers for this pair. The signatures method says they are different, while the partition refinement method says they are the same. Odd - and more investigation is needed before I am certain that geng has missed some graphs here...
Comments