Took another look at the CDK using classcycle, but this time I used the complete package that Taverna downloaded as part of the CDK plugin (which isn't working at the moment, for some reason).
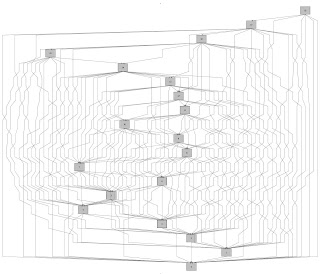
The easiest way to look at the results, really, is to export them as a CSV file, and look at it with a spreadsheet. Interestingly, the results show that it is CML that has the most layers. If I am understanding the idea of layers in classcycle correctly, it means something like the longest dependency path that ends in that class.
The top hit is the DictionaryTool from org.xmlcml.cml.tools, with a layer index of 32. The first CDK class with a high layer index is CMLWriter (29) then RSSWriter but most of the top 50 are CML classes. I guess it's not a bad thing, it's just a thing. A measurement.
edit: heh. The eclipse plugin for classcycle made this image for CDK:

Comments
I'll check out that class dependency stuff a bit more later... right now, the compile ensures clean build dependencies, but we still have to handcraft dependencies... and adding one (e.g. commit 12142) is cheap, but clean up is expensive...