Line-graphs of search-trees of molecular-graphs, that is. I should also point out that I am not using the cutting-edge development version of OMG, but rather the commit 30b08250efa4.... - sadly, I don't have java7 on this machine, so I can't run the latest versions.
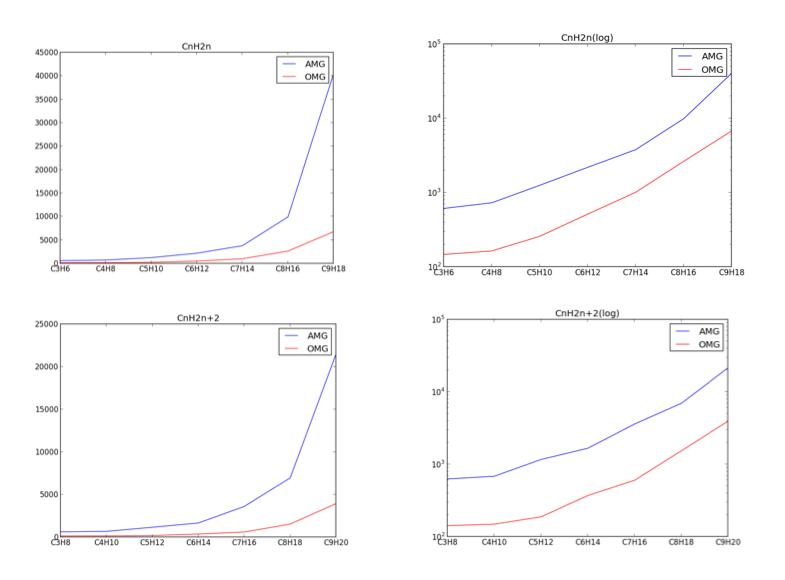
Anyway, it doesn't make much difference for the alkanes and alkenes. Here are the times in miliseconds, and log(t in ms) for CnH2n and CnH2n+2. Click for bigger, as always:
 Clearly AMG (in blue) is significantly slower than OMG (in red), roughly by 10 times. On the other hand, the picture is surprisingly different if we add in a few oxygens:
Clearly AMG (in blue) is significantly slower than OMG (in red), roughly by 10 times. On the other hand, the picture is surprisingly different if we add in a few oxygens:
 Weird, but I suspect that this kind of problem has been fixed in more recent versions of OMG. User "mmajid" seems to have been doing some interesting experiments with using bliss instead of nauty, multithreading, and semicanonical checking.
Weird, but I suspect that this kind of problem has been fixed in more recent versions of OMG. User "mmajid" seems to have been doing some interesting experiments with using bliss instead of nauty, multithreading, and semicanonical checking.
Anyway, it doesn't make much difference for the alkanes and alkenes. Here are the times in miliseconds, and log(t in ms) for CnH2n and CnH2n+2. Click for bigger, as always:

Comments
just a general heads up, these are great improvements,
considering its a "tiny" version update.
C7H16O2 from 510 sec --> 4 sec = 127 fold faster
C6H14O3 from 387 sec --> 5 sec = 77x speed increase.
That is great news. Actually even stuff like C7H16O3
that was a time-out in the old version runs now in 27 seconds.
Think about a parallel version with 32 threads and it runs in 1 sec.
...and from there another 100-fold increase to match MOLGEN-Demo.
Anyway, I think its great and if some graph people would chime in
and contribute code it surely would even go faster :-)
Cheers
Tobias